

Referenz String-Objekt
Juli 2024
Eigentlich sollte das eine Kurz-Referenz werden, aber dann begannen die Abenteuer ...
Eine Test-Zeichenkette
Diese Zeichenkette enthält ein Emotiocon. Das müssen wir uns genauer ansehen.
Vermutlich wird es Normalität werden, dass beliebige Unicode-Zeichen in Zeichenketten vorkommen.
Alle folgenden Darstellungen und Beispiele verwenden Text in einer UTF-8-Codierung!
Ausnahmeweise verwenden wir die Kommandozeile von GNU/Linux und
analysieren die Zeichenkette mit dem Kommando od. Eine Zeichenkette mit Emoticon auf der Kommandozeile hat vielleicht
noch nicht jeder gesehen.

Das Kommando zeigt die einzelnen Zeichen gesichert und zuverlässig byteweise an.
Wir erkennen dass das Emoticon aus 4 Byte besteht. Diese 4 Bytes erscheinen (sinnvollerweise) nicht als Zeichen, sondern als Oktalzahlen.
Die Zeichenkette besteht somit aus 16 Bytes.
| Code | Ausgabe | Erklärung |
|---|---|---|
const testString = "Hallo🙋, Welt";
const myBlob = new Blob(testString),
ausgabe("out2", myBlob.size);
|
Das verrät uns auch JavaScript,
wenn wir die Zeichenkette in ein Blob setzen und die Bytezahl abfragen. |
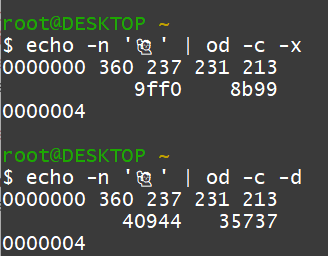 |
Mit zusätzliche Optionen kann
od noch mehr. Diese beiden Aufrufe zeigen eine Analyse nur des Emoticons.
Die 4 Bytes werden zu jeweils zwei Bytepaaren zusammengefasst.
Wie sehen die Darstellung der zwei Zahlen als Hex- und als Dezimalzahlen.
Byte-Paare bzw. 16-Bit-Einheiten werden uns auch in JavaScript begegnen.
|
| Code | Ausgabe | Erklärung |
|---|---|---|
const iterator = testString[Symbol.iterator]();
let iterObj = iterator.next(); let index = 0;
let ergebnis = '';
while(! iterObj.done)
{
ergebnis += index.toString()
+ ':' + iterObj.value + "<br>";
iterObj = iterator.next();
index++;
}
ausgabe("out3", ergebnis);
|
Ein String-Objekt besitzt so etwas wie einen eingebauten Iterator,
der einen Durchlauf durch alle Zeichen ermöglicht.
Interessant dabei: Das Emoticon wird als ein Zeichen erkannt,
und so gibt es 13 Zeichen in unserer Zeichenkette, gezählt von 0 bis 12.
|
|
let laenge = testString.length;
ausgabe("out4", laenge); |
Wir haben also zwei Längenangaben, 16 Bytes oder 12 (Unicode-)Zeichen.
Und nun kommt noch eine dritte Länge hinzu, die liefert die Eigenschaften length
des String-Objekts. |
|
ergebnis = '';
for (let i=0; i < laenge; i++)
{
ergebnis += i.toString() + ': '
+ testString[i] + "<br>";
}
ausgabe("out4s", ergebnis); |
Eine for-Schleife, die von
0 bis length die Zeichenkette durchläuft, verrät uns mehr.
Wir lassen den Index ausgeben und mithilfe der Array-Schreibweise das betreffende Zeichen.Wir sehen, dass unser Emoticon offenbar in zwei undefinierte Zeichen auf Index 5 und 6 zerlegt ist. Das entspricht genau den 16-Bit-Werten, die wir beim Kommdo
od gesehen haben.
Dadurch verschieben sich die Indexe danach. Befindet sich in der Iterator-Ausgabe beispielsweise das Zeichen Wauf Index 8, so ist es hier auf Index 9 zu finden. |
Das liegt daran, dass JavaScript intern jedes Zeichen eines Strings wie UTF-16 kodiert darstellt,
also gibt
Für Unicode-Zeichen, die aus mehr als 2 Bytes bestehen, hat das zur Folge, dass sie zerlegt werden.
Noch weitere String-Methoden
length die Anzahl von (internen) Zeichen zu je 2 Bytes zurück.
Genauer beschrieben ist das im MDN.
Für Unicode-Zeichen, die aus mehr als 2 Bytes bestehen, hat das zur Folge, dass sie zerlegt werden.
Noch weitere String-Methoden
denkenin diesen 16-Bit-Einheiten.
| Code | Ausgabe | Erklärung |
|---|---|---|
let code = testString.charCodeAt(5);
ausgabe("out5", code);
let zeichen = String.fromCharCode(code);
ausgabe("out6", zeichen);
code = testString.charCodeAt(9);
ausgabe("out7", code);
zeichen = String.fromCharCode(code);
ausgabe("out8", zeichen); |
|
Die Methode charCodeAt(index)
liefert den Zeichencode anhand eines Indexes.
Das Umgekehrte, die Wandlung von Code zu Zeichen, bewirkt die statische Methode String.fromCharCode(code).
Auf Index 5 wird leider nicht unser Emoticon erkannt, und das Zeichen W(Zeichencode 87) begegnet uns auf Index 9. |
zeichen = testString.at(9);
ausgabe("out7", zeichen);
zeichen = testString.at(1);
ausgabe("out8", zeichen);
zeichen = testString.at(-1);
ausgabe("out9", zeichen); |
|
Die Methode at(index) liefert keinen Zeichencode, sondern das Zeichen selbst
und ist damit eine Alternative zur Array-Schreibweise. Das Wwird auch auf Index 9 gesehen. Die Methode verträgt negative Index-Werte. In dem Fall wird die Zeichenkette rückwärts analysiert. Mit Index 0 ist nunmal das erste Zeichen definiert, folglich befindet sich auf 1 das zweite Zeichen, -1 jedoch zeigt das letzte Zeichen. |
Gibt es nun eine Möglichkeit, beliebige Unicode-Zeichen per Index vollständig zu erkennen?
Die Methode
Die Methode
codePointAt(index) kann genau das.
| Code | Ausgabe | Erklärung |
|---|---|---|
code = testString.codePointAt(5);
ausgabe("out12", code);
zeichen = String.fromCodePoint(code);
ausgabe("out13", zeichen);
code = testString.codePointAt(6);
ausgabe("out14", code);
zeichen = String.fromCodePoint(code);
ausgabe("out15", zeichen);
code = testString.codePointAt(9);
ausgabe("out16", code);
zeichen = String.fromCodePoint(code);
ausgabe("out17", zeichen); |
|
Auf Index 5 wird die Dezimalzahl 128587 erkannt und das ist genau der Zeichencode unseres Emoticons.
Die Methode
fromCodePoint(code) wandelt so gewonnen Code wieder in das entsprechende Zeichen.
Man kann diesen Code auch nutzen für die HTML-Darstellung dieses Zeichen, und zwar so: 🙋 (🙋).
Allerdings wird auch bei diesen Methoden die Zeichenkette in 16-Bit-Einheiten gesehen,
und daher wird mit Index 6 der hintere Teil des Emoticons erwischt.
Und das Zeichen W befindet sich auf Index 9.
|
Die Frage ist, inwieweit das stört. In der Regel wird kaum ein numerischer Zeichencode manuell vorgeben,
sondern von Teilzeichenketten die Position bestimmt oder Teilzeichenketten werden ausgetauscht usw.